4 Subsetting
4.1 Introduction
R’s subsetting operators are fast and powerful. Mastering them allows you to succinctly perform complex operations in a way that few other languages can match. Subsetting in R is easy to learn but hard to master because you need to internalise a number of interrelated concepts:
There are six ways to subset atomic vectors.
There are three subsetting operators,
[[,[, and$.Subsetting operators interact differently with different vector types (e.g., atomic vectors, lists, factors, matrices, and data frames).
Subsetting can be combined with assignment.
Subsetting is a natural complement to str(). While str() shows you all the pieces of any object (its structure), subsetting allows you to pull out the pieces that you’re interested in. For large, complex objects, I highly recommend using the interactive RStudio Viewer, which you can activate with View(my_object).
Quiz
Take this short quiz to determine if you need to read this chapter. If the answers quickly come to mind, you can comfortably skip this chapter. Check your answers in Section 4.6.
What is the result of subsetting a vector with positive integers, negative integers, a logical vector, or a character vector?
What’s the difference between
[,[[, and$when applied to a list?When should you use
drop = FALSE?If
xis a matrix, what doesx[] <- 0do? How is it different fromx <- 0?How can you use a named vector to relabel categorical variables?
Outline
Section 4.2 starts by teaching you about
[. You’ll learn the six ways to subset atomic vectors. You’ll then learn how those six ways act when used to subset lists, matrices, and data frames.Section 4.3 expands your knowledge of subsetting operators to include
[[and$and focuses on the important principles of simplifying versus preserving.In Section 4.4 you’ll learn the art of subassignment, which combines subsetting and assignment to modify parts of an object.
Section 4.5 leads you through eight important, but not obvious, applications of subsetting to solve problems that you often encounter in data analysis.
4.2 Selecting multiple elements
Use [ to select any number of elements from a vector. To illustrate, I’ll apply [ to 1D atomic vectors, and then show how this generalises to more complex objects and more dimensions.
4.2.1 Atomic vectors
Let’s explore the different types of subsetting with a simple vector, x.
x <- c(2.1, 4.2, 3.3, 5.4)Note that the number after the decimal point represents the original position in the vector.
There are six things that you can use to subset a vector:
-
Positive integers return elements at the specified positions:
-
Negative integers exclude elements at the specified positions:
x[-c(3, 1)] #> [1] 4.2 5.4Note that you can’t mix positive and negative integers in a single subset:
x[c(-1, 2)] #> Error in x[c(-1, 2)]: only 0's may be mixed with negative subscripts -
Logical vectors select elements where the corresponding logical value is
TRUE. This is probably the most useful type of subsetting because you can write an expression that uses a logical vector:x[c(TRUE, TRUE, FALSE, FALSE)] #> [1] 2.1 4.2 x[x > 3] #> [1] 4.2 3.3 5.4In
x[y], what happens ifxandyare different lengths? The behaviour is controlled by the recycling rules where the shorter of the two is recycled to the length of the longer. This is convenient and easy to understand when one ofxandyis length one, but I recommend avoiding recycling for other lengths because the rules are inconsistently applied throughout base R.Note that a missing value in the index always yields a missing value in the output:
x[c(TRUE, TRUE, NA, FALSE)] #> [1] 2.1 4.2 NA -
Nothing returns the original vector. This is not useful for 1D vectors, but, as you’ll see shortly, is very useful for matrices, data frames, and arrays. It can also be useful in conjunction with assignment.
x[] #> [1] 2.1 4.2 3.3 5.4 -
Zero returns a zero-length vector. This is not something you usually do on purpose, but it can be helpful for generating test data.
x[0] #> numeric(0) -
If the vector is named, you can also use character vectors to return elements with matching names.
(y <- setNames(x, letters[1:4])) #> a b c d #> 2.1 4.2 3.3 5.4 y[c("d", "c", "a")] #> d c a #> 5.4 3.3 2.1 # Like integer indices, you can repeat indices y[c("a", "a", "a")] #> a a a #> 2.1 2.1 2.1 # When subsetting with [, names are always matched exactly z <- c(abc = 1, def = 2) z[c("a", "d")] #> <NA> <NA> #> NA NA
NB: Factors are not treated specially when subsetting. This means that subsetting will use the underlying integer vector, not the character levels. This is typically unexpected, so you should avoid subsetting with factors:
y[factor("b")]
#> a
#> 2.14.2.2 Lists
Subsetting a list works in the same way as subsetting an atomic vector. Using [ always returns a list; [[ and $, as described in Section 4.3, let you pull out elements of a list.
4.2.3 Matrices and arrays
You can subset higher-dimensional structures in three ways:
- With multiple vectors.
- With a single vector.
- With a matrix.
The most common way of subsetting matrices (2D) and arrays (>2D) is a simple generalisation of 1D subsetting: supply a 1D index for each dimension, separated by a comma. Blank subsetting is now useful because it lets you keep all rows or all columns.
a <- matrix(1:9, nrow = 3)
colnames(a) <- c("A", "B", "C")
a[1:2, ]
#> A B C
#> [1,] 1 4 7
#> [2,] 2 5 8
a[c(TRUE, FALSE, TRUE), c("B", "A")]
#> B A
#> [1,] 4 1
#> [2,] 6 3
a[0, -2]
#> A CBy default, [ simplifies the results to the lowest possible dimensionality. For example, both of the following expressions return 1D vectors. You’ll learn how to avoid “dropping” dimensions in Section 4.2.5:
a[1, ]
#> A B C
#> 1 4 7
a[1, 1]
#> A
#> 1Because both matrices and arrays are just vectors with special attributes, you can subset them with a single vector, as if they were a 1D vector. Note that arrays in R are stored in column-major order:
vals <- outer(1:5, 1:5, FUN = "paste", sep = ",")
vals
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] "1,1" "1,2" "1,3" "1,4" "1,5"
#> [2,] "2,1" "2,2" "2,3" "2,4" "2,5"
#> [3,] "3,1" "3,2" "3,3" "3,4" "3,5"
#> [4,] "4,1" "4,2" "4,3" "4,4" "4,5"
#> [5,] "5,1" "5,2" "5,3" "5,4" "5,5"
vals[c(4, 15)]
#> [1] "4,1" "5,3"You can also subset higher-dimensional data structures with an integer matrix (or, if named, a character matrix). Each row in the matrix specifies the location of one value, and each column corresponds to a dimension in the array. This means that you can use a 2 column matrix to subset a matrix, a 3 column matrix to subset a 3D array, and so on. The result is a vector of values:
4.2.4 Data frames and tibbles
Data frames have the characteristics of both lists and matrices:
When subsetting with a single index, they behave like lists and index the columns, so
df[1:2]selects the first two columns.When subsetting with two indices, they behave like matrices, so
df[1:3, ]selects the first three rows (and all the columns)35.
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])
df[df$x == 2, ]
#> x y z
#> 2 2 2 b
df[c(1, 3), ]
#> x y z
#> 1 1 3 a
#> 3 3 1 c
# There are two ways to select columns from a data frame
# Like a list
df[c("x", "z")]
#> x z
#> 1 1 a
#> 2 2 b
#> 3 3 c
# Like a matrix
df[, c("x", "z")]
#> x z
#> 1 1 a
#> 2 2 b
#> 3 3 c
# There's an important difference if you select a single
# column: matrix subsetting simplifies by default, list
# subsetting does not.
str(df["x"])
#> 'data.frame': 3 obs. of 1 variable:
#> $ x: int 1 2 3
str(df[, "x"])
#> int [1:3] 1 2 3Subsetting a tibble with [ always returns a tibble:
4.2.5 Preserving dimensionality
By default, subsetting a matrix or data frame with a single number, a single name, or a logical vector containing a single TRUE, will simplify the returned output, i.e. it will return an object with lower dimensionality. To preserve the original dimensionality, you must use drop = FALSE.
-
For matrices and arrays, any dimensions with length 1 will be dropped:
-
Data frames with a single column will return just the content of that column:
df <- data.frame(a = 1:2, b = 1:2) str(df[, "a"]) #> int [1:2] 1 2 str(df[, "a", drop = FALSE]) #> 'data.frame': 2 obs. of 1 variable: #> $ a: int 1 2
The default drop = TRUE behaviour is a common source of bugs in functions: you check your code with a data frame or matrix with multiple columns, and it works. Six months later, you (or someone else) uses it with a single column data frame and it fails with a mystifying error. When writing functions, get in the habit of always using drop = FALSE when subsetting a 2D object. For this reason, tibbles default to drop = FALSE, and [ always returns another tibble.
Factor subsetting also has a drop argument, but its meaning is rather different. It controls whether or not levels (rather than dimensions) are preserved, and it defaults to FALSE. If you find you’re using drop = TRUE a lot it’s often a sign that you should be using a character vector instead of a factor.
4.2.6 Exercises
-
Fix each of the following common data frame subsetting errors:
-
Why does the following code yield five missing values? (Hint: why is it different from
x[NA_real_]?)x <- 1:5 x[NA] #> [1] NA NA NA NA NA -
What does
upper.tri()return? How does subsetting a matrix with it work? Do we need any additional subsetting rules to describe its behaviour? Why does
mtcars[1:20]return an error? How does it differ from the similarmtcars[1:20, ]?Implement your own function that extracts the diagonal entries from a matrix (it should behave like
diag(x)wherexis a matrix).What does
df[is.na(df)] <- 0do? How does it work?
4.3 Selecting a single element
There are two other subsetting operators: [[ and $. [[ is used for extracting single items, while x$y is a useful shorthand for x[["y"]].
4.3.1 [[
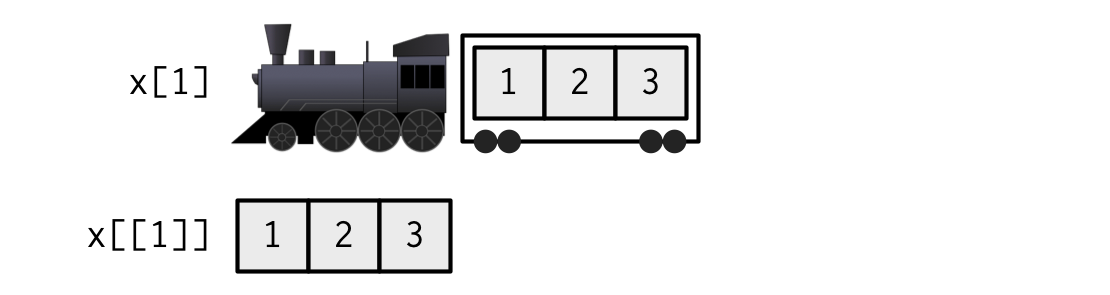
[[ is most important when working with lists because subsetting a list with [ always returns a smaller list. To help make this easier to understand we can use a metaphor:
If list
xis a train carrying objects, thenx[[5]]is the object in car 5;x[4:6]is a train of cars 4-6.— @RLangTip, https://twitter.com/RLangTip/status/268375867468681216
Let’s use this metaphor to make a simple list:
x <- list(1:3, "a", 4:6)
When extracting a single element, you have two options: you can create a smaller train, i.e., fewer carriages, or you can extract the contents of a particular carriage. This is the difference between [ and [[:
When extracting multiple (or even zero!) elements, you have to make a smaller train:
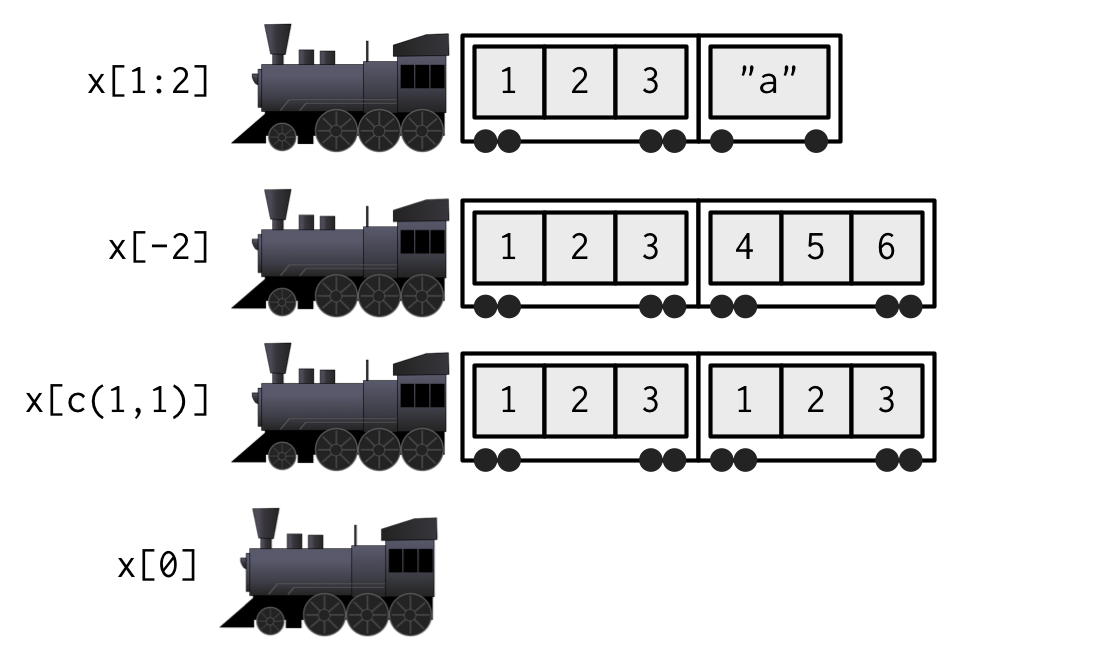
Because [[ can return only a single item, you must use it with either a single positive integer or a single string. If you use a vector with [[, it will subset recursively, i.e. x[[c(1, 2)]] is equivalent to x[[1]][[2]]. This is a quirky feature that few know about, so I recommend avoiding it in favour of purrr::pluck(), which you’ll learn about in Section 4.3.3.
While you must use [[ when working with lists, I’d also recommend using it with atomic vectors whenever you want to extract a single value. For example, instead of writing:
for (i in 2:length(x)) {
out[i] <- fun(x[i], out[i - 1])
}It’s better to write:
for (i in 2:length(x)) {
out[[i]] <- fun(x[[i]], out[[i - 1]])
}Doing so reinforces the expectation that you are getting and setting individual values.
4.3.2 $
$ is a shorthand operator: x$y is roughly equivalent to x[["y", exact = FALSE]]. It’s often used to access variables in a data frame, as in mtcars$cyl or diamonds$carat. One common mistake with $ is to use it when you have the name of a column stored in a variable:
var <- "cyl"
# Doesn't work - mtcars$var translated to mtcars[["var"]]
mtcars$var
#> NULL
# Instead use [[
mtcars[[var]]
#> [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4The one important difference between $ and [[ is that $ automatically does (left-to-right) partial matching without warning:
x <- list(abc = 1)
x$a
#> [1] 1
x[["a"]]
#> NULL
To help avoid this behaviour I highly recommend setting the global option warnPartialMatchDollar to TRUE:
options(warnPartialMatchDollar = TRUE)
x$a
#> Warning in x$a: partial match of 'a' to 'abc'
#> [1] 1(For data frames, you can also avoid this problem by using tibbles, which never do partial matching.)
4.3.3 Missing and out-of-bounds indices
It’s useful to understand what happens with [[ when you use an “invalid” index. The following table summarises what happens when you subset a logical vector, list, and NULL with a zero-length object (like NULL or logical()), out-of-bounds values (OOB), or a missing value (e.g. NA_integer_) with [[. Each cell shows the result of subsetting the data structure named in the row by the type of index described in the column. I’ve only shown the results for logical vectors, but other atomic vectors behave similarly, returning elements of the same type (NB: int = integer; chr = character).
row[[col]] |
Zero-length | OOB (int) | OOB (chr) | Missing |
|---|---|---|---|---|
| Atomic | Error | Error | Error | Error |
| List | Error | Error | NULL |
NULL |
NULL |
NULL |
NULL |
NULL |
NULL |
If the vector being indexed is named, then the names of OOB, missing, or NULL components will be <NA>.
The inconsistencies in the table above led to the development of purrr::pluck() and purrr::chuck(). When the element is missing, pluck() always returns NULL (or the value of the .default argument) and chuck() always throws an error. The behaviour of pluck() makes it well suited for indexing into deeply nested data structures where the component you want may not exist (as is common when working with JSON data from web APIs). pluck() also allows you to mix integer and character indices, and provides an alternative default value if an item does not exist:
4.3.4 @ and slot()
There are two additional subsetting operators, which are needed for S4 objects: @ (equivalent to $), and slot() (equivalent to [[). @ is more restrictive than $ in that it will return an error if the slot does not exist. These are described in more detail in Chapter 15.
4.4 Subsetting and assignment
All subsetting operators can be combined with assignment to modify selected values of an input vector: this is called subassignment. The basic form is x[i] <- value:
I recommend that you should make sure that length(value) is the same as length(x[i]), and that i is unique. This is because, while R will recycle if needed, those rules are complex (particularly if i contains missing or duplicated values) and may cause problems.
With lists, you can use x[[i]] <- NULL to remove a component. To add a literal NULL, use x[i] <- list(NULL):
x <- list(a = 1, b = 2)
x[["b"]] <- NULL
str(x)
#> List of 1
#> $ a: num 1
y <- list(a = 1, b = 2)
y["b"] <- list(NULL)
str(y)
#> List of 2
#> $ a: num 1
#> $ b: NULLSubsetting with nothing can be useful with assignment because it preserves the structure of the original object. Compare the following two expressions. In the first, mtcars remains a data frame because you are only changing the contents of mtcars, not mtcars itself. In the second, mtcars becomes a list because you are changing the object it is bound to.
mtcars[] <- lapply(mtcars, as.integer)
is.data.frame(mtcars)
#> [1] TRUE
mtcars <- lapply(mtcars, as.integer)
is.data.frame(mtcars)
#> [1] FALSE4.5 Applications
The principles described above have a wide variety of useful applications. Some of the most important are described below. While many of the basic principles of subsetting have already been incorporated into functions like subset(), merge(), and dplyr::arrange(), a deeper understanding of how those principles have been implemented will be valuable when you run into situations where the functions you need don’t exist.
4.5.1 Lookup tables (character subsetting)
Character matching is a powerful way to create lookup tables. Say you want to convert abbreviations:
x <- c("m", "f", "u", "f", "f", "m", "m")
lookup <- c(m = "Male", f = "Female", u = NA)
lookup[x]
#> m f u f f m m
#> "Male" "Female" NA "Female" "Female" "Male" "Male"Note that if you don’t want names in the result, use unname() to remove them.
unname(lookup[x])
#> [1] "Male" "Female" NA "Female" "Female" "Male" "Male"4.5.2 Matching and merging by hand (integer subsetting)
You can also have more complicated lookup tables with multiple columns of information. For example, suppose we have a vector of integer grades, and a table that describes their properties:
grades <- c(1, 2, 2, 3, 1)
info <- data.frame(
grade = 3:1,
desc = c("Excellent", "Good", "Poor"),
fail = c(F, F, T)
)Then, let’s say we want to duplicate the info table so that we have a row for each value in grades. An elegant way to do this is by combining match() and integer subsetting (match(needles, haystack) returns the position where each needle is found in the haystack).
id <- match(grades, info$grade)
id
#> [1] 3 2 2 1 3
info[id, ]
#> grade desc fail
#> 3 1 Poor TRUE
#> 2 2 Good FALSE
#> 2.1 2 Good FALSE
#> 1 3 Excellent FALSE
#> 3.1 1 Poor TRUEIf you’re matching on multiple columns, you’ll need to first collapse them into a single column (with e.g. interaction()). Typically, however, you’re better off switching to a function designed specifically for joining multiple tables like merge(), or dplyr::left_join().
4.5.3 Random samples and bootstraps (integer subsetting)
You can use integer indices to randomly sample or bootstrap a vector or data frame. Just use sample(n) to generate a random permutation of 1:n, and then use the results to subset the values:
df <- data.frame(x = c(1, 2, 3, 1, 2), y = 5:1, z = letters[1:5])
# Randomly reorder
df[sample(nrow(df)), ]
#> x y z
#> 5 2 1 e
#> 3 3 3 c
#> 4 1 2 d
#> 1 1 5 a
#> 2 2 4 b
# Select 3 random rows
df[sample(nrow(df), 3), ]
#> x y z
#> 4 1 2 d
#> 2 2 4 b
#> 1 1 5 a
# Select 6 bootstrap replicates
df[sample(nrow(df), 6, replace = TRUE), ]
#> x y z
#> 5 2 1 e
#> 5.1 2 1 e
#> 5.2 2 1 e
#> 2 2 4 b
#> 3 3 3 c
#> 3.1 3 3 cThe arguments of sample() control the number of samples to extract, and also whether sampling is done with or without replacement.
4.5.4 Ordering (integer subsetting)
order() takes a vector as its input and returns an integer vector describing how to order the subsetted vector36:
To break ties, you can supply additional variables to order(). You can also change the order from ascending to descending by using decreasing = TRUE. By default, any missing values will be put at the end of the vector; however, you can remove them with na.last = NA or put them at the front with na.last = FALSE.
For two or more dimensions, order() and integer subsetting makes it easy to order either the rows or columns of an object:
# Randomly reorder df
df2 <- df[sample(nrow(df)), 3:1]
df2
#> z y x
#> 5 e 1 2
#> 1 a 5 1
#> 4 d 2 1
#> 2 b 4 2
#> 3 c 3 3
df2[order(df2$x), ]
#> z y x
#> 1 a 5 1
#> 4 d 2 1
#> 5 e 1 2
#> 2 b 4 2
#> 3 c 3 3
df2[, order(names(df2))]
#> x y z
#> 5 2 1 e
#> 1 1 5 a
#> 4 1 2 d
#> 2 2 4 b
#> 3 3 3 cYou can sort vectors directly with sort(), or similarly dplyr::arrange(), to sort a data frame.
4.5.5 Expanding aggregated counts (integer subsetting)
Sometimes you get a data frame where identical rows have been collapsed into one and a count column has been added. rep() and integer subsetting make it easy to uncollapse, because we can take advantage of rep()s vectorisation: rep(x, y) repeats x[i] y[i] times.
4.5.6 Removing columns from data frames (character )
There are two ways to remove columns from a data frame. You can set individual columns to NULL:
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])
df$z <- NULLOr you can subset to return only the columns you want:
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])
df[c("x", "y")]
#> x y
#> 1 1 3
#> 2 2 2
#> 3 3 1If you only know the columns you don’t want, use set operations to work out which columns to keep:
4.5.7 Selecting rows based on a condition (logical subsetting)
Because logical subsetting allows you to easily combine conditions from multiple columns, it’s probably the most commonly used technique for extracting rows out of a data frame.
mtcars[mtcars$gear == 5, ]
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Porsche 914-2 26.0 4 120.3 91 4.43 2.14 16.7 0 1 5 2
#> Lotus Europa 30.4 4 95.1 113 3.77 1.51 16.9 1 1 5 2
#> Ford Pantera L 15.8 8 351.0 264 4.22 3.17 14.5 0 1 5 4
#> Ferrari Dino 19.7 6 145.0 175 3.62 2.77 15.5 0 1 5 6
#> Maserati Bora 15.0 8 301.0 335 3.54 3.57 14.6 0 1 5 8
mtcars[mtcars$gear == 5 & mtcars$cyl == 4, ]
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Porsche 914-2 26.0 4 120.3 91 4.43 2.14 16.7 0 1 5 2
#> Lotus Europa 30.4 4 95.1 113 3.77 1.51 16.9 1 1 5 2Remember to use the vector boolean operators & and |, not the short-circuiting scalar operators && and ||, which are more useful inside if statements. And don’t forget De Morgan’s laws, which can be useful to simplify negations:
-
!(X & Y)is the same as!X | !Y -
!(X | Y)is the same as!X & !Y
For example, !(X & !(Y | Z)) simplifies to !X | !!(Y|Z), and then to !X | Y | Z.
4.5.8 Boolean algebra versus sets (logical and integer )
It’s useful to be aware of the natural equivalence between set operations (integer subsetting) and Boolean algebra (logical subsetting). Using set operations is more effective when:
You want to find the first (or last)
TRUE.You have very few
TRUEs and very manyFALSEs; a set representation may be faster and require less storage.
which() allows you to convert a Boolean representation to an integer representation. There’s no reverse operation in base R but we can easily create one:
x <- sample(10) < 4
which(x)
#> [1] 2 3 4
unwhich <- function(x, n) {
out <- rep_len(FALSE, n)
out[x] <- TRUE
out
}
unwhich(which(x), 10)
#> [1] FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSELet’s create two logical vectors and their integer equivalents, and then explore the relationship between Boolean and set operations.
(x1 <- 1:10 %% 2 == 0)
#> [1] FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE
(x2 <- which(x1))
#> [1] 2 4 6 8 10
(y1 <- 1:10 %% 5 == 0)
#> [1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE
(y2 <- which(y1))
#> [1] 5 10
# X & Y <-> intersect(x, y)
x1 & y1
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
intersect(x2, y2)
#> [1] 10
# X | Y <-> union(x, y)
x1 | y1
#> [1] FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE TRUE
union(x2, y2)
#> [1] 2 4 6 8 10 5
# X & !Y <-> setdiff(x, y)
x1 & !y1
#> [1] FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE FALSE
setdiff(x2, y2)
#> [1] 2 4 6 8
# xor(X, Y) <-> setdiff(union(x, y), intersect(x, y))
xor(x1, y1)
#> [1] FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE FALSE
setdiff(union(x2, y2), intersect(x2, y2))
#> [1] 2 4 6 8 5When first learning subsetting, a common mistake is to use x[which(y)] instead of x[y]. Here the which() achieves nothing: it switches from logical to integer subsetting but the result is exactly the same. In more general cases, there are two important differences.
When the logical vector contains
NA, logical subsetting replaces these values withNAwhilewhich()simply drops these values. It’s not uncommon to usewhich()for this side-effect, but I don’t recommend it: nothing about the name “which” implies the removal of missing values.x[-which(y)]is not equivalent tox[!y]: ifyis all FALSE,which(y)will beinteger(0)and-integer(0)is stillinteger(0), so you’ll get no values, instead of all values.
In general, avoid switching from logical to integer subsetting unless you want, for example, the first or last TRUE value.
4.5.9 Exercises
How would you randomly permute the columns of a data frame? (This is an important technique in random forests.) Can you simultaneously permute the rows and columns in one step?
How would you select a random sample of
mrows from a data frame? What if the sample had to be contiguous (i.e., with an initial row, a final row, and every row in between)?How could you put the columns in a data frame in alphabetical order?
4.6 Quiz answers
Positive integers select elements at specific positions, negative integers drop elements; logical vectors keep elements at positions corresponding to
TRUE; character vectors select elements with matching names.[selects sub-lists: it always returns a list. If you use it with a single positive integer, it returns a list of length one.[[selects an element within a list.$is a convenient shorthand:x$yis equivalent tox[["y"]].Use
drop = FALSEif you are subsetting a matrix, array, or data frame and you want to preserve the original dimensions. You should almost always use it when subsetting inside a function.If
xis a matrix,x[] <- 0will replace every element with 0, keeping the same number of rows and columns. In contrast,x <- 0completely replaces the matrix with the value 0.A named character vector can act as a simple lookup table:
c(x = 1, y = 2, z = 3)[c("y", "z", "x")]